介绍
JavaScript我们都知道,作为前端必备的知识为大家所熟知,那Node.js大家又了解多少呢?
首先来看下Node.js官网对他的介绍
Node.js® is a JavaScript runtime built on Chrome’s V8 JavaScript engine.
直译过来就是Node.js是构建在谷歌的V8 JS引擎上运行的JavaScript。
看完并不能理解Node.js是什么,首先抛出几个问题
- V8引擎是什么?
- Node.js是什么?
- Node.js跟javascript有什么区别
下面来一一解释。
V8引擎是什么
- 是什么:随着chrome发布的JavaScript渲染引擎。
- 做什么:对JavaScript代码进行解释执行。
- 优势:更快。原因如下:
相比于其他JS引擎转换为字节码或者解释执行相比,V8引擎直接将代码编译成原生机器码(IA-32、X86-64、ARM、MIPS CPUs),并且使用了如内联缓存(inline cache)等技术来提高性能。同时,V8可以独立运行或者嵌入到C++应用程序中运行(本身是由C++实现的)。
如果需要对V8引擎有更详细的了解可以查看此文章: Google V8引擎,这里就不详细解释了。
Nodejs是什么
介绍完了V8引擎,Node.js是什么呢?
Node.js就是运行在服务端的javaScript。
原因:Node.js在V8引擎的基础上进行封装扩展,使用c/c++等语言开发了大量的服务器端操作(如文件操作、网络通信、操作系统API等),用于方便搭建快速响应、易于拓展的网络应用。
基础架构
了解Node.js的原理就要从整个架构图开始,如下为Node.js的基础架构图。

上面这个图为简单概括了下Node.js的架构,主要分为三层,下面来一一介绍:
- Node.js/APP:这部分是所有的js代码,包括Node.js的核心代码,npm install装载的模块以及你的code等。
- 桥接层:这一层的功能是用来将底层c/c++的代码接口提供给上层js代码使用(胶水代码)。主要有两个模块,Node.js Bindings、c/c++ Addons。其中Binding是用来桥接Node.js核心库的依赖(如zlib、OpenSSL、c-ares、http-parser 等),而Addons则是用来桥接我们自己实现的代码或者第三方库的模块。
- Node.js的依赖库:这部分为核心依赖底层库,主要包括V8、libuv以及其他底层依赖库,我们下面来详解这些模块。
底层依赖库介绍如下:
V8前面已经说过了,高性能的JavaScript引擎,这里就不赘述了。
libuv:C语言开发,主要提供事件循环(event loop)、异步网络I/O、文件系统I/O等能力。
other:其他底层依赖库主要提供了对系统底层功能的访问,如c-ares提供DNS解析能力。crypto(OpenSSL)提供加密能力,http提供网络服务,zlib提供解压能力等等。
介绍完这些,我们好像并不能理解Node.js那些特性如单线程、异步IO,事件驱动等,下面我们通过运行原理的介绍带大家去理解这些内容。
运行原理
接到上面的介绍,首先来说单线程,我们都知道现在的程序都讲究多线程,同时处理任务,因为cpu执行速度很快,而IO相对来说要慢很多,如果是一个线程跑,其他任务等待,会导致cpu有大量的空闲时间,不仅是资源的浪费,我们的程序执行速度也会变得非常慢。那Node.js为什么还要使用单线程呢,这不是在倒退吗?
这里就引出了异步IO,Nodejs的单线程是相对而言的,我们可以理解为一个主线程,多个从线程。主线程主要执行代码逻辑,完成程序的运行,而较为缓慢的IO操作则交给从线程完成,这里的操作是异步的,也就是主线程注册了任务继续处理后面的任务,等到注册的这个任务完成后主线程才开始执行,具体结构请看下图:
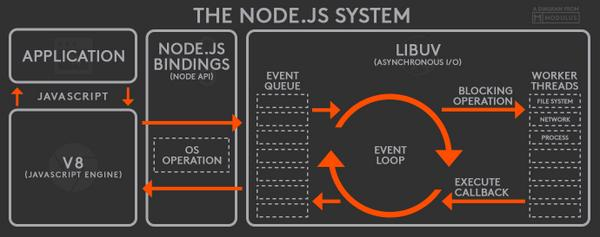
一个 Node.js 应用启动时,V8 引擎会执行你写的应用代码,保持一份观察者列表(注册在事件上的回调函数)。当事件发生时,它的回调函数会被加进一个事件队列。只要这个队列还有等待执行的回调函数,事件循环就会持续把回调函数从队列中拿出并执行。
在回调函数执行过程中,所有的 I/O 请求都会转发给工作线程处理。libuv 维持着一个线程池,包含四个工作线程(默认值,可配置)。文件系统 I/O 请求和 DNS 相关请求都会放进这个线程池处理;其他的请求,如网络、平台特性相关的请求会分发给相应的系统处理单元进行处理。
安排给线程池的这些 I/O 操作由 Node.js 的底层库执行,完成之后触发相应事件,对应的事件回调函数会被放入事件队列,等待执行后续操作。这就是一个事件在 Node.js 中执行的整个生命周期。
Node.js跟JavaScript有什么区别
最后一个问题,其实前面介绍完了,我们已经有了一个了解了,JavaScript是一门语言,而Node.js更像是是一个使用js这门异步IO的语言通过封装大量的后台库完成对高IO请求任务处理的服务端平台,一句话概括Node.js就是运行在服务端的javaScript。